网络
运输层
- 传输控制协议(TCP,Transmission Control Protocol)
- 用户数据报协议(UDP,User Datagram Protocol)
TCP和UDP协议有什么不同
- TCP是可靠的,有序的,面向链接的,传输数据较大,速度慢,具有数据重传机制,
- UDP是不可靠的,无序的,没有链接的,传输数据小,速度快,
- TCP一般用在文件传输,邮件等需要确保数据完整性,
- UDP一般用于实时应用,如QQ(由于tcp并发问题,选用udp再封装一层),直播等
TCP
- 在数据正确性与合法性上,TCP用一个校验和函数来检验数据是否有错误,在发送和接收时都要计算校验和;同时可以使用md5认证对数据进行加密。
- 在保证可靠性上,采用超时重传和捎带确认机制。
- 在流量控制上,采用滑动窗口协议,协议中规定,对于窗口内未经确认的分组需要重传。
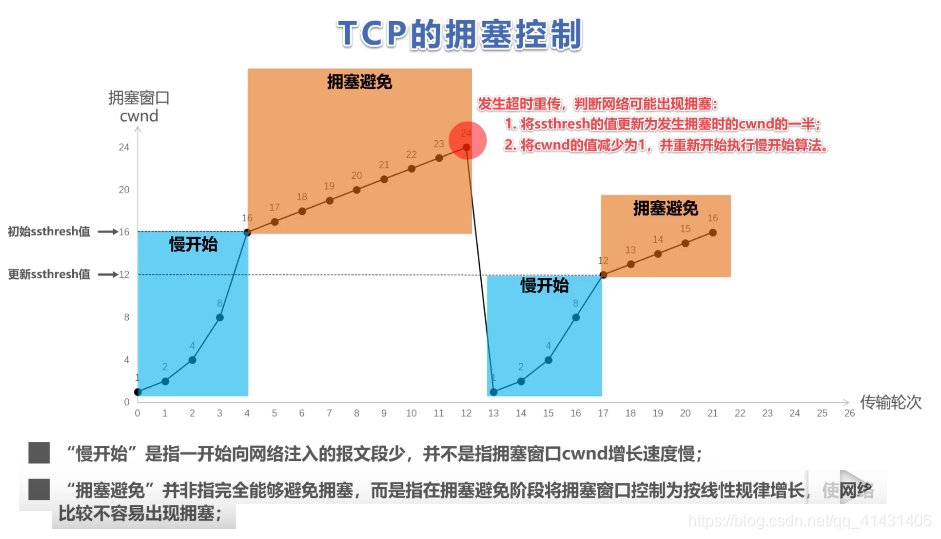
- TCP拥塞控制算法主要包括四个主要部分:
- 慢启动
- 拥塞避免
- 快速重传
- 快速恢复
名词解释
- MSS (最大传输段大小)
- MTU (最大传输单元)
计算机连接的网络的数据链路层的最大传送单元 - RTT (往返时延)
- SYN 表示建立连接
- FIN 表示关闭连接
- ACK 表示响应
TCP三次握手
TCP三次握手的过程如下:
- 客户端发送SYN(SEQ=x)报文给服务器端,进入SYN_SEND状态。
- 服务器端收到SYN报文,回应一个SYN (SEQ=y)ACK(ACK=x+1)报文,进入SYN_RECV状态。
- 客户端收到服务器端的SYN报文,回应一个ACK(ACK=y+1)报文,进入Established状态。
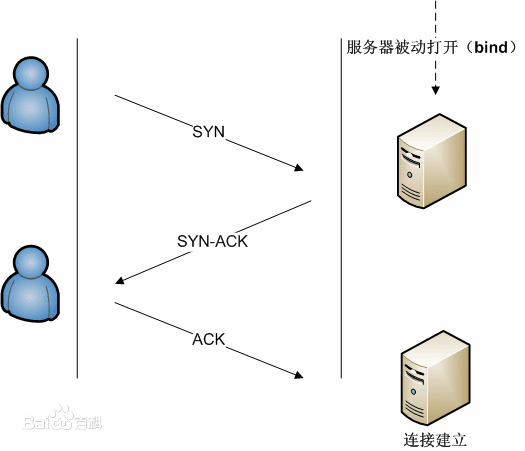
三次握手完成,TCP客户端和服务器端成功地建立连接,可以开始传输数据了。
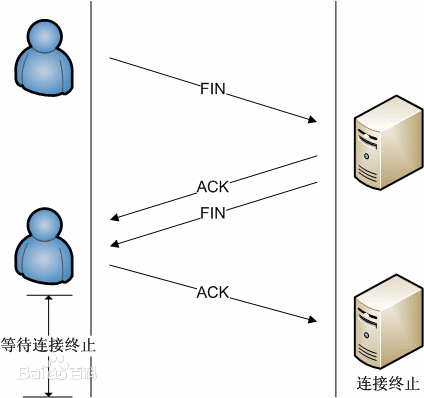
TCP四次挥手
- 某个应用进程首先调用close,称该端执行“主动关闭”(active close)。该端的TCP于是发送一个FIN分节,表示数据发送完毕。
- 接收到这个FIN的对端执行 “被动关闭”(passive close),这个FIN由TCP确认。 注意:FIN的接收也作为一个文件结束符(end-of-file)传递给接收端应用进程,放在已排队等候该应用进程接收的任何其他数据之后,因为,FIN的接收意味着接收端应用进程在相应连接上再无额外数据可接收。
- 一段时间后,接收到这个文件结束符的应用进程将调用close关闭它的套接字。这导致它的TCP也发送一个FIN。
- 接收这个最终FIN的原发送端TCP(即执行主动关闭的那一端)确认这个FIN。 [3]
应用层
Http协议
- (Hyper Text Transfer protocol)应用层,基于TCP/IP
- 问答模式
- 特点:简单快捷;灵活;无连接?;无状态 每次交互都是独立的
- 浏览器通常都会限制url长度在2K个字节
HTTP1.1 改动:
- 持久连接 解决了每次请求都会建立一次 TCP 连接的问题, 如果 Keep-Alive 设置为 true 每建立一次链接可以发送多次 Http 请求,但是这个多次请求是以队列的形式发送的,也就是第一个请求处理完才能处理第二个请求
- 请求管道化
- 增加缓存处理(新的字段如cache-control)
- 增加Host字段、支持断点传输等
HTTP2 改动:
- 二进制分帧
- 多路复用 就是在一个 TCP 连接中可以存在多条流。换句话说,也就是可以发送多个请求,对端可以通过帧中的标识知道属于哪个请求。通过这个技术,可以避免 HTTP 旧版本中的队头阻塞问题,极大的提高传输性能。
- 头部压缩
- 服务器推送
Request结构
- 请求行 (请求类型,要访问的资源,以及所使用的版本)
- 请求头 (Host,User-Agent,Content-Type,Content-Length,Connection(keep-Alive))
- 空行,用来分隔请求头和请求主体
- 请求主体
Response
- 状态行(协议版本号,状态码,状态消息) HTTP/1.1 200 OK
- 消息报头
- 空行
- 响应正文
HTML请求方法
- GET
- POST
- PUT
- HEAD
- DELETE
- PATCH
- OPTIONS
GET
GET 用于从指定资源请求数据。
查询字符串(名称/值对)是在 GET 请求的 URL 中发送的:
1
/test/demo_form.php?name1=value1&name2=value2
- 请求可被缓存
- 请求保留在浏览器历史记录中
- 请求可被收藏为书签
- 请求不应在处理敏感数据时使用
- 请求有长度限制
- 请求只应当用于取回数据(不修改)
POST
POST 用于将数据发送到服务器来创建/更新资源。
通过 POST 发送到服务器的数据存储在 HTTP 请求的请求主体中:
1
2
3
POST /test/demo_form.php HTTP/1.1
Host: w3school.com.cn
name1=value1&name2=value2
- 请求不会被缓存
- 请求不会保留在浏览器历史记录中
- 不能被收藏为书签
- 请求对数据长度没有要求
PUT
PUT 用于将数据发送到服务器来创建/更新资源。
POST 和 PU T之间的区别在于 PUT 请求是幂等的(idempotent)。也就是说,多次调用相同的 PUT 请求将始终产生相同的结果。相反,重复调用POST请求具有多次创建相同资源的副作用。
GET和POST有什么不同
- GET 用于从指定资源请求数据。
- GET请求数据是写在URL中的,POST请求数据是写在RequestBody中的
- 在标准规定下 GET 请求不允许携带RequestBody,如果RequestBody偷偷藏了数据,处不处理完全看服务器程序员习惯
- GET产生一个TCP数据包;POST产生两个TCP数据包。 对于GET方式的请求,浏览器会把http header和data一并发送出去,服务器响应200(返回数据); 而对于POST,浏览器先发送header,服务器响应100 continue,浏览器再发送data,服务器响应200 ok(返回数据)。 并不是所有浏览器都会在POST中发送两次包,Firefox就只发送一次。
- GET是无副作用的,POST可能有副作用
w3school GET和POST对比
| 请求类型 | GET | POST |
|---|---|---|
| 后退按钮/刷新 | 无害 | 数据会被重新提交(浏览器应该告知用户数据会被重新提交)。 |
| 书签 | 可收藏为书签 | 不可收藏为书签 |
| 缓存 | 能被缓存 | 不能缓存 |
| 编码类型 | application/x-www-form-urlencoded | application/x-www-form-urlencoded 或 multipart/form-data。为二进制数据使用多重编码。 |
| 历史 | 参数保留在浏览器历史中。 | 参数不会保存在浏览器历史中。 |
| 对数据长度的限制 | 是的。当发送数据时,GET 方法向 URL 添加数据;URL 的长度是受限制的(URL 的最大长度是 2048 个字符)。 | 无限制。 |
| 对数据类型的限制 | 只允许 ASCII 字符。 | 没有限制。也允许二进制数据。 |
| 安全性 | 与 POST 相比,GET 的安全性较差,因为所发送的数据是 URL 的一部分。 在发送密码或其他敏感信息时绝不要使用 GET ! |
POST 比 GET 更安全,因为参数不会被保存在浏览器历史或 web 服务器日志中。 |
| 可见性 | 数据在 URL 中对所有人都是可见的。 | 数据不会显示在 URL 中。 |
OkHttp
Okhttp优点
- HTTP/2 support allows all requests to the same host to share a socket.
- Connection pooling reduces request latency (if HTTP/2 isn’t available).
- Transparent GZIP shrinks download sizes.
- Response caching avoids the network completely for repeat requests.
- 方便的API
- 易扩展性,
- 完整的生态
retrofit
SSL
解决的问题
- 窃听风险(eavesdropping):第三方可以获知通信内容。
- 篡改风险(tampering):第三方可以修改通信内容。
- 冒充风险(pretending):第三方可以冒充他人身份参与通信。
SSL过程
- 当你的浏览器向服务器请求一个安全的网页(通常是 https://)
- 服务器就把它的证书和公匙发回来
- 浏览器检查证书是不是由可以信赖的机构颁发的,确认证书有效和此证书是此网站的。
- 浏览器中随机生成一对对称秘钥,并使用公钥(服务器端的)加密该对称秘钥,将它和对称加密后的URL一起发送到服务器
- 服务器用自己的私匙解密了你发送的钥匙。然后用这把对称加密的钥匙给你请求的URL链接解密。
- 服务器用你发的对称钥匙给你请求的网页加密。你也有相同的钥匙就可以解密发回来的网页了
相关思考
- 为什么要用非对称加密 窃听风险,如果采用对称加密,如果并且密码被窃听到,那么通话内容就会被破解。如果采用非对称加密,那么即使第三者拿到公钥也无法得到对话内容
- CA解决了什么问题 冒充风险,CA证书能确定通话对象是域名所对应的对象
- 为什么采用非对称加密和对称加密结合的方式 为了提高性能,对称密钥要比非对称加密算法更容易计算。用非对称加密交换对称加密的密钥保证了对称加密密钥的安全性,所以用非对称加密内容也是安全的
- 为什么CA证书能确定目标身份
视频会议用的UDP
UDP 没有拥塞控制,一直会以恒定的速度发送数据。即使网络条件不好,也不会对发送速率进行调整。这样实现的弊端就是在网络条件不好的情况下可能会导致丢包,但是优点也很明显,在某些实时性要求高的场景(比如电话会议)就需要使用 UDP 而不是 TCP。